了解了fits文件的结构后,准备3000条光谱做一次聚类试一下,其中恒星、星系、类星体光谱各1000条。
然后就在3000个Lamost的光谱fits文件中将他们的光谱提取出来放在一个二维numpy数组中,这时发现他们每一条光谱的波长数量不一样,虽然都是3900个左右,但都不尽相同,特征数量不一样就不能直接训练。我去请教一下学长,学长说真是数据就是这样,需要用一些方法预处理一下,使维度相同。
感觉挺棘手的,这些光谱的起始和终止波长有或多或少的差别,某个元素的发射线在不同光谱上对应的波长也有一点差别,比如说Na元素在A光谱上对应的是5020.15Å,在B光谱上可能是5021.46Å,挨得很近,但不相同。问问学长、查查资料,发现要用类似窗口滑动思想的一些方法提取光谱线。
于是就先试着截取一段波长的训练一下试试,截取一个每个光谱都包含的波长范围,取的是3838Å到8914Å,截取出来后维度仍不一样,都在2750维附近,可见每个光谱观测的波长的步长不完全一致。
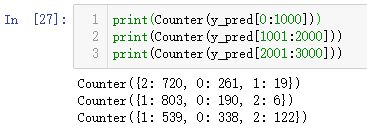
然后就想着直接取中间2750个波长的值得了,取了之后把光谱画出来发现每个光谱的尺度不同,有的几十、有的在1000附近,但是形状是一样的,如下图:
(那个高的发射线也太长了吧。。)
把每个光谱归一化一下,尺度做成一样的应该就能训练了。方法是(x-x_min)/(x_max-x_min)
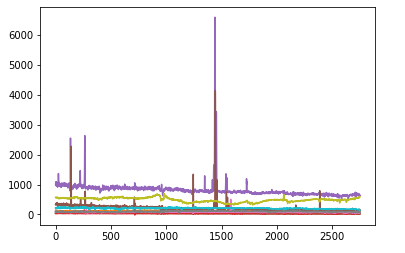
将每个光谱的值范围归一化在0-1内,画出光谱图为:
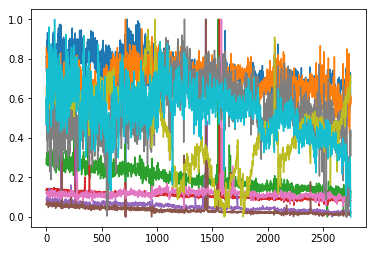
还是有点乱,应该是有的光谱最大值和最小值差的太大。那就换成减均值除方差的正则化方法处理,处理后画出两类天体的各10个光谱图如下:
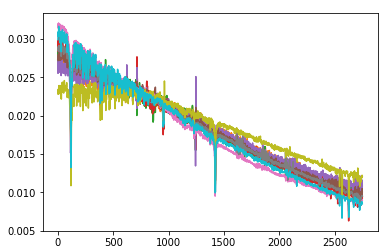
这样看着可以,虽然个别发射线还是很长,但多数的值还是重叠的。
这样就能丢进算法里跑了,先来一个k-means试试。
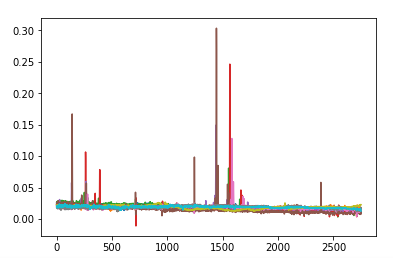
K值就去3,3000x2750的数据跑一次竟然挺快,但是准确率有点差,因该是没进行放射线特征提取,只简单截取的原因。每种天体被分类到的类别个数: